BI Explorer
Better insight into patient data
Make your medical data actionable
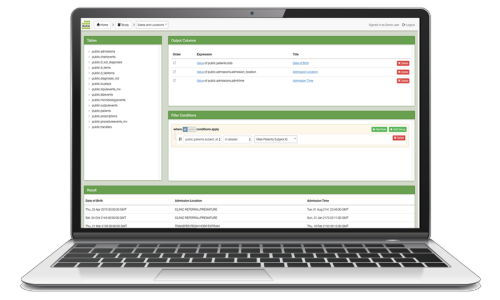
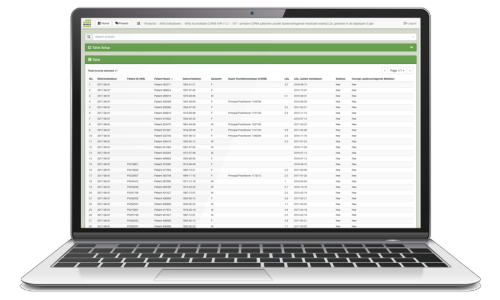
BI Explorer is a web-based Business Intelligence tool that provides medical professionals with a powerful set of tools to get quick insight into medical data. National quality reports or key performance indicators can be displayed in a dashboard, a report, or an interactive table. Drilling down to the underlying data and the use of filtering, grouping and pivot operations lead to new insights and better informed decision making.
BI Explorer is successfully used to:
- Find outliers as defined by national parameters or relative to a patient group
- Find deviations from average organization performance
- Compare medication administration to lab results
- Process and outcomes trend analyses
- Cross-organization and cross-practitioner competitive analysis
- Risk factor analysis
BI Explorer benefits:
- Deploy in a multi-tenant fashion
- Integrate with authentication services and show/hide/mask PII data based on user role
- Filter on any aspect of the data (e.g. demographics, diagnosis, medication, process, labresults)
- Group on organization or sub-organization levels with standard aggregates
- Calculate group fractions, e.g. the fraction of patients within an organisation with BMI < 30
- Create pivot tables, e.g. show KPIs over age groups
- Store combinations of filters, groupings or pivots as presets
- Share presets with other users belonging to the same tenant
As a service provider, you can create any number of standard presets that can be shared with healthcare professionals so they can view compliance to organizational practices and indicators and drill down to the patients that need extra attention.